Too long, didn’t read: You can use this Ruby script to query Archive.org’s recently-launched TVNews archive and download JSON files with the results. It’s great for tracking how frequently a person or topic shows up in U.S. televised news broadcasts.
(cross-posted at Nieman Journalism Lab)
One of the goals of our research at the MIT Center for Civic Media is to better quantify media attention. We want to know which stories, people, and events our society is paying attention to, which we are missing, and the role our media plays in determining what we see. We’re working with the fine people at Harvard’s Berkman Center to build out Media Cloud. In addition to building tools, we also investigate case studies of news stories that offer greater insight into how the news plays out. You may have seen Yochai Benkler’s investigation into SOPA and PIPA and a networked movement’s success driving the media narrative:
Last year, I wrote about the Trayvon Martin story’s ascent from local blurb to national media trend. This initial analysis relied on a mixture of sources: interviews with key actors, petition data from Change.org, audience reach metrics from various news sources, Google Trends, visualizations of physical front pages of newspapers, and the Pew Project for Excellence in Journalism’s News Coverage Index.
After the post attracted some interest, we investigated further with additional datasets. With the help of my colleague Erhardt Graeff, we added Media Cloud to the mix. Media Cloud allows us to see who’s talking about the story on blogs and webpages, which voices are dominating the discussion, and which words and frames they’re introducing to the narrative. (More on our findings to follow). I also added Twitter firehose data to the mix, thanks to General Sentiment.
Even though we’re excited about the potential of participatory media to help shape what we pay attention to, our media research consistently finds that broadcast media — primarily TV — still plays a critical role in the amplification of voices. This was especially true for the Trayvon Martin story, which moved relatively quickly from obscurity to wall-to-wall cable news coverage.
At the same time, the team at Archive.org, that quintessential Internet resource, was busy launching their TV News archive. The search tool queries more than 410,000 broadcasts, dating from June 2009 up to 24 hours ago. (They are working to extend the archive further back into history.) The search results deliver video clips ready to play the section of video containing your query. It’s a fun interface for exploration, but if you’re looking at how a story trends over several months, you need something more systematic, and may want to use our script.
The Archive.org team is working to build out the platform and improve the user experience. They don’t currently have capacity to guide and support researchers at the moment, but they do want to get this data in the hands of the curious as soon as possible. To that end, they’ve given me permission to share this quick Ruby script I wrote with the help of my colleague Rahul Bhargava.
How to use the script
- Download the file from GitHub.
- Open it in a text editor (like TextWrangler or BBEdit), edit line 11 of the code to change
'Your Query'to your preferred search term(s), and save it - Go to the command line (Terminal on a Mac, DOS or Cygwin in Windows)
- Navigate to the folder that contains the script
- Type in
ruby archive.org-getter.rband hit enter
Your results will show up in the same directory as the script itself. The results returned will be in JSON, the open data format. You can adjust how many results to return at once (by changing the ROWS variable in the script), but go easy on Archive.org’s servers: You’ll get your results faster (nearly instantly) in smaller batches of 200 or so.
Once you have your data, you can combine, clean, and parse it with Google Refine. I found ProPublica’s guide to cleaning messy data really helpful. You may also want to de-duplicate, because Archive.org records TV news broadcasts on the both the east and west coasts.
What you can do with it
Analyze a story: You could search for a specific story, like the recent controversial Steubenville rape case, and quickly get a sense of which news companies are covering the case and which words they use to talk about it. You can also share links to specific clips with your friends and colleagues.
You could also investigate our professional media’s treatment of a broader topic. You could trace the spread of the phrase “Obamacare” or watch the many breathless news segments covering “technology.”
 Visualize TV news data: You’ll also have the data you need to visualize the lifespan of a story on televised news broadcasts. Archive.org renders a small line graph in your search results, but the JSON data will allow you to do much more.
Visualize TV news data: You’ll also have the data you need to visualize the lifespan of a story on televised news broadcasts. Archive.org renders a small line graph in your search results, but the JSON data will allow you to do much more.
For example, in the Trayvon Martin case study, we ended up normalizing the data with the number of Trayvon mentions in the printed press, blogosphere, on Twitter, and across other channels to determine when interest began and peaked. As you can see with the green bars below, TV news was an important channel in the early stages of the Trayvon Martin story.
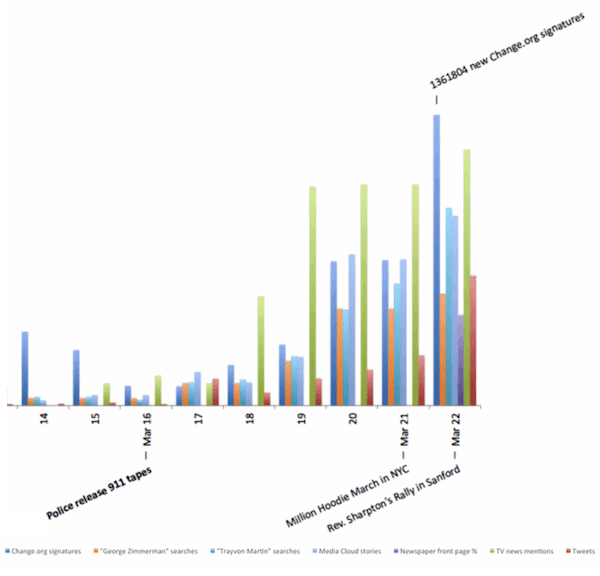
This data source helped us determine that TV news led the press and other media in making (and keeping) Trayvon Martin national news.
Do an advanced search: The advanced search settings allow you to restrict your search by program, station, date, topic, and clip length. If you customize your search in the web interface, you’ll see which parameters get added to the search results URL. You can then copy and paste those into your Ruby script to add the same filters to your bulk data download.
Compare station-by-station coverage: You could also look at how a story or topic between the East and West coasts of the United States. Archive.org’s news database contains recordings from Washington, D.C., San Francisco, and national programs. Here’s a list of the station call letters and their locations.
Borrow DVDs of programs: If you want more than the short clip containing your search query, you can borrow a DVD recording of the full broadcast from the Internet Archive. To do so, you can either show up in person at Archive.org’s San Francisco library or pay a (sometimes refundable) $25-75 fee to have it mailed to you.